RegEx
Regular Expression
RegEx or Regular Expressions is a sequence of characters that specifies a search pattern in text. This can be used for finding strings of text in large files quickly and easily and can be used in conjunction with 'Find & Replace' operations.
RegEx Basics
In order to use RegEx in Notepad++ you will need to make a few changes to the "Find" tool (press CTRL+F or go to the
"Search" menu at the top, then select "Find"). Specifically, you will need to change the "Search Mode" to "Regular Expression" - see the
screen grab below: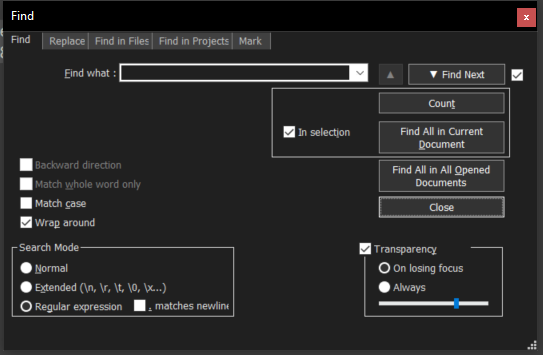
You will see the "Search Mode" options at the bottom left of this screen. It is also recommended to have "Match Case" ticked as well, otherwise this will ignore some regular expressions
Basic special characters
A few basic special characters to be aware of
| Character | Matches |
|---|---|
| . or \C | Matches any character, but not 'newline' sequences (unless ". matches new line" is ticked) |
| \☒ | Where ☒ is a RegEx special character, \ is the escape character for this. E.g searching for a period/fullstop "." would match any character, so you would need to escape this by searching for \. |
| \b | The back space character, in most cases functions as word boundary |
| \n | "Line Feed" character, functionally the end of line character, especially in Unix systems |
| \r | "Carriage return" character, functionally end of line character in DOS/Windows systems Not the same as \R, see below |
| \R | Any newline sequence. May match more than one character. Cannot be used in lookbehinds as it has a variable length |
| \t | "Tab" character |
| \xℕℕ | Specify a single character with code ℕℕ, where each ℕ is a hexadecimal digit. What these stand for depends on the text encoding. For example; \xE9 may match é or θ depending on the code page in an ANSI encoded document. |
| [set] | Match a set of characters, for example [abd] means find any of the characters 'a', 'b' or 'c'. Ranges can also be used as a set, for example [a-m] would find any character from (and |
| [^ set ] | Do not match one of the characters in the set. For example [^A-Za-z] will match any non alphabetic character (numbers, control characters and so on) |
| | | Used for matching this or that, e.g. this|that will match "this" or "that". |
Character Properties
RegEx can also be used to find characters with particular properties using the special characters below.
| Property | Positive Match | Negative Match |
|---|---|---|
| Digits (numbers) | \d | \D |
| Lowercase | \l | \L |
| Space characters | \s | \S |
| Uppercase | \u | \U |
| Word characters | \w | \W |
| Horizontal space | \h | \H |
| Vertical Space | \v | \V |
Multiplying Operators
Sometimes when you are trying to match patterns of characters, you may want to match four digits in a row. You could type this out like \d\d\d\d to find four numbers in a row or you could make the RegEx more susinct and use a multiplier.
| Operator | Explanation |
|---|---|
| + | This matches 1 or more of the previous character (as many as it can, also known as 'greedy'). For example, the pattern Be+d matches Bed, Beed, Beeed and so on. This can also be used with sets; [0-9]+ will match any length of number, so long as the number characters are consectutive. |
| * | This matches 0 or more of the previous character (greedy). [Be*d] will match Bd, Bed, Beed and so on. |
| ? | Will match 0 or 1 of the previous character. In this case, [Be?d] will match Bd and Bed but not Beed |
| {ℕ} | matches ℕ copies of the element it is applied to (where ℕ is a decimal number) |
There are more multiplying operators, but these will not be covered here for the time being. So to use the example above (to search for 4 digits appearing together) we could type \d{4} or you could do [0-9]{4}.
Anchors
Anchors Anchors are used to represent "zero-length position in the line" instead of a particular character, for example the start or end of a line.
| Anchor | Explanation |
|---|---|
| ^ | Matches start of a line, except when used in a set (in which case it will make it a negative match for the set) |
| $ | Matches end of a line |
| \< | Matches start of a word (using Scintilla's definition of words) |
| \> | Matches end of a word |
| \b | Matches either the start or end of word |
| \B | Not a word boundary. This is a location between two word characters or between two non-word characters |
| \A or \` | Matches the start of a file |
| \Z or \' | Matches the end of a file |
Capture Groups
Capture A group is part of a RegEx pattern inside a set of parentheses ( and ). As an example, a RegEx pattern (ham) would capture a single group containing the letters 'h', 'a' and 'm' (so 'ham' would match, 'hamster' would match, 'gingham' would match and so on). For extra control, capture groups can be nested. It should be noted that groups are not the same as sets; sets match any of the characters in them, whereas a group will match that exact pattern. That is to say [A-Z] is not the same as (A-Z). The former will match any single character from A to Z and the latter will match the exact string "A-Z". Groups can come in useful with something like listing out file names. Say for example you want to list out all the .JPG files you have and they were named in a predictable format, you could search using RegEx pattern ^(IMG\d+\.jpg)$. Now you may also want to capture the file names without the extension, so you would use ^(IMG\d+)\.jpg$ or if you wanted to check for upper and lower case extensions you could use something like ^(IMG\d+)\.(jpg|JPG)$
Worked Example
For the RAID log below (this is only part of the log), I wanted to find what the last time stamps were before the controller started booting up and copy these lines only. Here is a sample of the file that I was searching. In the original file, there were 20 times where the controller was booting up. In this sample there is only one, however it should be sufficient to practice with.
Sample TTy log, click to view
02/16/22 14:05:57.419: C0:FlashSize: 0x2000000 02/16/22 14:05:57.534: C0:TtyAlignErase 3 : fae = e8400000, persist256kAlignAddr e84c0000 02/16/22 14:05:57.650: C0:LogAlignErase: Aligning Erased flash blocks [0xe8210000-0xe8240000], logErasedPtrBitmap:0 02/16/22 14:06:26.121: C0:Skinny flash done. Erasing old image header. 02/16/22 14:06:26.189: C0:EVT#01124- 02/16/22 14:06:26: 21=Flashing image: NVDT v5.1400.06-0007 02/16/22 14:06:26.191: C0:ImageAddress: Existing:0xe8f00000 New:0xe8f00000 02/16/22 14:06:26.191: C0:FlashSize: 0x2000000 02/16/22 14:06:26.306: C0:TtyAlignErase 3 : fae = e8400000, persist256kAlignAddr e84c0000 02/16/22 14:06:26.422: C0:LogAlignErase: Aligning Erased flash blocks [0xe8210000-0xe8240000], logErasedPtrBitmap:0 02/16/22 14:06:27.720: C0:FlashFind: Searching for CPLD :Found @:0x80(App:any) 02/16/22 14:06:27.735: C0:CPLD image exists with version 1, incoming version 1 02/16/22 14:06:27.736: C0:CPLD incoming version 1 02/16/22 14:06:27.737: C0:Incoming CPLD image is not newer than existing CPLD image.Skipping 02/16/22 14:06:27.738: C0:FlashWrite: Flashing of Lattice CPLD succeeded 02/16/22 14:06:27.772: C0:EVT#01125-02/16/22 14:06:27: 21=Flashing image: SGFW v3.00.01 02/16/22 14:06:27.773: C0:ImageAddress: Existing:0xe8f40000 New:0xe8f40000 02/16/22 14:06:27.774: C0:FlashSize: 0x2000000 02/16/22 14:06:27.901: C0:TtyAlignErase 3 : fae = e8400000, persist256kAlignAddr e84c0000 02/16/22 14:06:28.000:C0:LogAlignErase: Aligning Erased flash blocks [0xe8210000-0xe8240000], logErasedPtrBitmap:0 02/16/22 14:06:30.015: C0:Clearing the snapdump as the new firmware package is flashed 02/16/22 14:06:30.050: C0:EVT#01126- 02/16/22 14:06:30: 22=Flash of new firmware image(s)complete 02/16/22 14:06:30.051: C0:OFU Not possible. Disabling OCR at HW 02/16/22 14:06:30.090: C0:CtrlOFUDebugPrintFlags: OFUrequest=0, OFUpossible=1,OFUVersionNotCompatible=0 T9: C0:EVT#01127- T9: 0=Firmware initialization started (PCI ID 0015/1000/1f3d/1028) T9: C0:EVT#01128-T9: 1=Firmware version 5.140.01-3461 T9: C0:OOB_InitParams: OOBPhysBinding = 1 T9: C0:I2C 4 reset! T9: C0:I2Chandle obtained for MUX [4]0x40 T9: C0:MfgMsg: DRAM SIZE=0 MB T9: C0:Init flash timings : FlashTimeNs 78 NvsTimeNs 32 NvmeCRS 1 T9: C0:phy intIndex extIndex T9: C0: 00 00 ff T9: C0: 01 00 ff T9: C0: 02 00 ff T9: C0: 03 00 ff T9: C0: 04 01 ff T9: C0: 05 01 ff T9: C0: 06 01 ff T9: C0: 07 01 ff T9: C0: 08 02 ff T9: C0: 09 02 ff T9: C0: 0a 02 ff T9: C0: 0b 02 ff T9: C0: 0c 03 ff T9: C0: 0d 03 ff T9: C0: 0e 03 ff T9: C0: 0f 03 ff T9: C0: MFC data (All values are in hex): T9: C0: vendorId/deviceId=1000/0015, subVendorId/subDeviceId=1028/1f3d T9: C0: OEM=2, SubOem=0, isRaidKeySecondary=0 T9: C0: MFC Features: T9: C0: clusterDisable=1, disableSAS=0, maxDisks=0, enableRaid6=0, disableWideCache=0 T9: C0: disableRaid5=1, enableSecurity=0,enableReducedFeatureSet=0 T9: C0: enableCTIO=1, enableSSC=0, enableSSCWB=0 T9: C0: MFCD: sasAddr=52cea7f0c4fde600, phyPolarity=00 phyPolaritySplit 00 T9: C0: backgroundRate=1e, stripeSize=7(64K), flushTime=4 T9: C0: writeBack=0, readAhead=0, cacheWhenBBUBad=0, cachedIo=0 T9: C0: smartMode=0(6), alarmDisable=1, coercion=1(128M), zcrConfig=0(Undefined) T9: C0: dirtyLedShowsDriveActivity=0, biosContinueOnError=1, spindownMode=0(None) T9: C0: allowedDeviceTypes=0(SAS/SATA), allowMixInEnclosure=1 T9: C0: allowMixInLD=0, allowSataInCluster=0 T9: C0: allowSSDMixInLD=0, allowMixSSDHDDInLD=0 T9: C0: maxChainedEnclosures=2, disableCtrlR=1, enableWebBios=0 T9: C0: directPdMapping=0,biosEnumerateLds=1 T9: C0: restoreHotSpareOnInsertion=0, exposeEnclosureDevices=0 T9: C0: maintainPdFailHistory=0, disablePuncturing=0 zeroBasedEnclEnumeration=1, disableBootCLI=1 T9: C0: quadPortConnectorMap=0, driveActivityLed=1, disableAutoDetectBackplane=0 T9: C0: enableLedHeaders=0, useFdeOnly=1, delayPOST=0, enableCrashDump=0, enableLDBBM=1 T9: C0: allowUnCertifiedHDDs=1, treatR1EAsR10=1, maxLdsPerArray=0, disableOnlineCtrlReset=0 T9: C0: failPdOnSMARTer=0, nonRevertibleSpares=0 T9: C0: disablePowerSavings=7f, spinDownTime=1e, perfTunerMode=0, enableJBOD=1, disableCacheBypass=1, ttyLogInFlash=1 T9: C0: breakMirrorRAIDSupport=1, disableJoinMirror=1 T9: C0: enableEmergencySpare=0, useGlobalSparesForEmergency=0, useUnconfGoodForEmergency=0 T9: C0: enableShieldState=0, enableDriveWCEforRebuild=0 T9: C0: blockSSDWriteCacheChange=0, disableHII=0, detectCMETimer:3c T9: C0: SMARTerEnabled=0, SSDSMARTerEnabled=1 enable512eSupport=0 T9: C0: disableImmediateIO=0, enableLargeIOSupport=1, enableTransportReady=0 T9: C0: SESVPDAssociationTypeInMultiPathCfg=0 T9: C0: adapterPersonality=1 T9: C0: autoCfgOption=0, ignore64ldRestriction=0 maxLDs=0, predictiveFailureLED=0 enableFDETypeMix=0 T9: C0: disableSafeModeOnOcr=1 T9: C0:MFC Manufacturing data: T9: C0: date=08/03/21, sn="17U00B8", reworkDate=08/03/21, rev="A02" T9: C0:disabledFeatures : 2 T9: C0:can_flush = 0 T9: C0:initFreeCDBs dmaframe 7fbf9360 xorFrame 7fbfd360 T9: C0:dmaCompletionMgrInit T9: C0:CtrlInfoPropInitialize disableUnmap 1 T9: C0:SnapDumpInit:Initializing SnapDump Module - curNumSupproted 1 maxNumSupported 1 offloadNum 0 triggerMinNumSecBeforeOcr 19 T9: C0:ArmFlushTrace: TraceCapEn is not set. TMC is not in RUNNING state.....!!! T9: C0:PTM has not exited programming mode T9: C0:ArmResetTrace: Failed to reset PTM T9: C0:f907c000: 00000001 8d294004 00018ff6 00000000 .....@)......... T9: C0:f907c010: 00000002 00000000 00000000 00000000 ................ T9: C0:f907c020: 0001dcdd 0100000c 00000000 00000000 ................ T9: C0:f907c030: 00000000 00000000 00000000 00000000 ................ T9: C0:f907c040: f73b1ad9 71acb6ed 169f6e76 f97fc3ec ..;....qvn...... T9: C0:f907c050: ddd7edc8 f53269f7 66bfe9bc 742fde63 .....i2....fc./t T9: C0:f907c060: 00000000 00000000 00000000 00000000 ................ T9: C0:f907c070: 00000000 00000000 00000000 00000000 ................ T9: C0:f907c080: 0000a501 0000ed01 0000ff01 0000dd01 ................ T9: C0:f907c090: 00001c01 00003901 00006901 0000e601 .....9...i...... T9: C0:f907c0a0: 00000000 00000000 00000000 00000000 ................ T9: C0:f907c0b0: 00000000 00000000 00000000 00000000 ................ T9: C0:f907c0c0: 00000000 00000000 ........ T9: C0:Configured Trace FSM successfully T9: C0:FlashFind: Searching for CPLD :Found @:0x80(App:any) T10: C0:CPLD version 001
In order to find this, I needed to find the line where the controller is starting and then find the line before it. Certainly this is something that could be done manually, but depending on the number of lines, this could take a few seconds to a few hours. Why not use the tools?
Before we use the tools, we need to understand how to find the line which indicates that the controller is booting. In this case, the line "0=Firmware initialization started". To find this, we can use the pattern 0=Firmware and this will find exactly "0=Firmware" as there are no special characters involved. Great, so now we can find where the controller started booting up. But we wanted to capture the line before it.
We can capture a whole line using the pattern "^.+\R". We can break this down as follows:
- ^ matches start of line [[#Anchors|anchor]]
- . matches any character
- + matches one or more of the previous character
- \R matches any end of line anchor
This pattern will capture any whole line in the file, not quite what we want. So we need to tell it how to find a specific line, i.e. the line immediately before "0=Firmware" appears. This means that we need to tell it to match two things. So we can put the patterns that we have already created in to groups, thusly; (^.+\R)(0=Firmware).
Does that work now? Not quite, now it matches nothing. This is not desirable. Can you see why it doesn't work?
It does not work because it is trying to find a whole line immediately followed by "0=Firmware" which doesn't exist, the lines look like this:
02/16/22 14:06:30.090: C0:CtrlOFUDebugPrintFlags: OFUrequest=0, OFUpossible=1, OFUVersionNotCompatible=0 T9: C0:EVT#01127-T9: 0=Firmware .......
So we're not capturing '*T9: C0:EVT#01127-T9: *"' (note that white spaces are important when using regular expressions).
Looking at the line with '0=Firmware' on it, we see that it starts with 'T'. How can we capture that?
Were you right? click to reveal the answer
We can capture it using the start of line anchors '^' and the letter 'T' to give ^TGreat, so now we can capture every single line starting with "T" - there are a lot of these. How does that help us? Well we need to be able to establish where the line that we want ends - it ends with the start of the line containing the "0=Firmware" pattern. If we then add that on to our new RegEx pattern, we get ^.+\R^T. In turn this matches all lines that have a start, end of line character (\R) another start of line and then the character "T". This has narrowed our search down somewhat, however there are many lines that fit this pattern.
From here we need to do two things:
- Narrow the pattern to make it match more specific lines
- Stop the pattern matching more than the what we want/need it to
So we know we do not want to match beyond "0=Firmware", so this will form part of the pattern. So we need to think about the pattern to match a string starting with the line start anchor (^) and ending with "0=Firmware". So, using the previous pattern, we could do ^.+\R^T and add on a pattern that matches anything leading up to "0=Firmware". The reason for matching any pattern is that we are not always sure what comes after ^T. So putting it together, we would get ^.+\R^T.+0=Firmware. Great! Now we've captured the exact line we are looking for but we have half a line that we do not need. So how to exclude that part of the result?
To do this, we need to think about [[#Capture Groups|capture groups]]. We can use these to match a pattern within a pattern or even to ignore sections of it. In this case, we wish to ignore the section ^T.+0=Firmware. So lets put this in a group by enclosing it in parenthesis thusly ^.+\R(^T.+0=Firmware). But wait, this is still capturing the same thing as it was before. So we need to change the pattern to say we do not want the part in the group. We can do that by excluding the part that we don't want (however we still need to make the match to ensure we are getting the correct line). In order to exclude a group, we can add ?= at the start of the group like this (?=^T.+0=Firmware). Lets add this to the part of the pattern to match the whole line; ^.+\R(?=T.+0=Firmware). This will now match the line before the "0=Firmware" line.
Job done.
Hopefully this goes someway to illustrate the power of regular expressions. These are used in all sorts of applications and programming languages. Across different languages, the basic idea is the same, however the specific implementation may be slightly nuanced.
For further reading on the implementation used in Notepad++, you can check out the extensive documentation.